[Object Detection] 2. R-CNN : 딥러닝을 이용한 첫 2-stage Detector
저번 포스팅에서는 Object Detection의 전체적인 흐름에 대해서 알아보았습니다.
[Object Detection] 1. Object Detection 논문 흐름 및 리뷰
Deep Learning 을 이용한 Object Detection의 최신 논문 동향의 흐름을 살펴보면서 Object Detection 분야에 대해서 살펴보고, 구조가 어떤 방식으로 되어있으며 어떤 방식으로 발전되어 왔는지 살펴보고자 한다...
nuggy875.tistory.com

이번 포스팅에서는 2-stage detector R-CNN계열의 선두주자이자,
Object Detection 분야에 최초로 Deep Learning(CNN)을 적용시킨
R-CNN 논문을 소개해드리고자 합니다.
논문 링크 : https://arxiv.org/pdf/1311.2524.pdf
⊙ R-CNN (CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation
2012년 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 AlexNet이 세상에 공개된 이후
CNN은 이미지 분류(Classification) 분야에 있어서 당연하게 사용되는 표준처럼 되어버렸습니다.
CNN이 이미지 분류(Classification) 분야에서 엄청난 성적을 거두었음에도
Object Detection 분야에 바로 적용되지는 못했는데요.
이미지 분류(classification)는 한 개의 객체(Object)가 그려져 있는 이미지가 있을 때
이 객체가 무엇인지 알아내는 문제입니다.
이와 다르게 물체인식(Object Detection) 알고리즘은
이미지 내에 관심이 있는 객체의 위치(Region of Interest)에
물체의 위치를 알려주기 위한 Bounding Box를 그려줘야 하고,
다수의 Bounding Box를 다양한 Object 종류에 대하여 찾아줘야 하기 때문에
이미지 분류 보다는 훨씬 복잡한 문제입니다.


때문에 2012년 CNN이 세상에 알려지고, Object Detection 분야에는 적용되지 못하고 있다가,
2014년 R-CNN의 등장으로 CNN을 Object Detection 분야에 최초로 적용시켰고
CNN을 이용한 검출 방식이 Classification 뿐만 아닌 Object Detection 분야에도
높은 수준의 성능을 이끌어 낼 수 있다는 것을 보여줬습니다.
TMI : 비슷한 시기에 나온 OverFeat논문이 먼저 적용시켰다는 말도 있지만,
이미지 대회에 OverFeat이 먼저 나왔고, 논문이 투고된건 시기상으로 R-CNN이 먼저였고
R-CNN이 훨신 뛰어난 성능을 보여줍니다.
OverFeat 논문 : https://arxiv.org/pdf/1312.6229.pdf
R-CNN은 VOC2012 (Visual Object Classes Challenge)에서
이전의 방법보다 30%가 넘는 큰 성능향상을 보였고
Object Detection 문제에서 큰 뿌리같은 존재가 되었습니다.
이후 R-CNN을 수정, 보완하여 성능, 속도 등을 향상시킨
R-CNN 계열의 논문들(R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN...)은
모두 R-CNN 구조를 바탕으로 하게 됩니다.

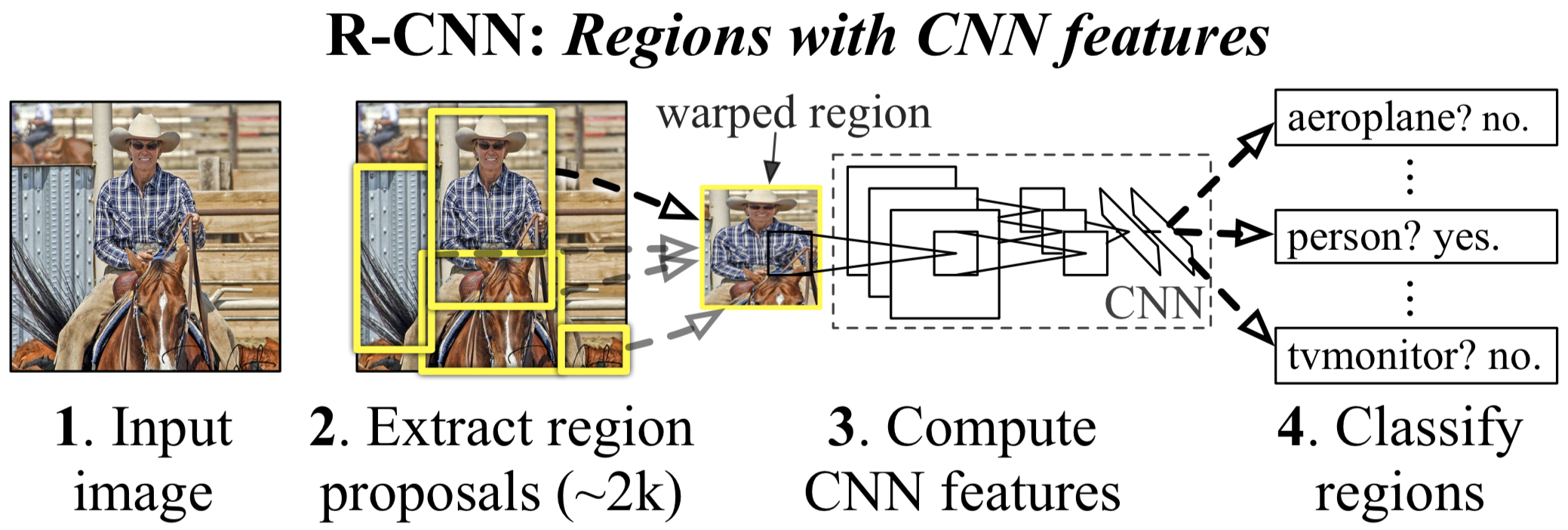
논문에서 소개하는 R-CNN의 구조는 다음과 같습니다.
간단하게 설명하면 아래 순서와 같습니다.
1. 이미지를 input으로 집어 넣는다.
2. 2000개의 영역(Bounding Box)을 Selective Search 알고리즘을 통해 추출하여 잘라낸다(Cropping).
2-1. 이를 CNN모델에 넣기 위해 같은 사이즈(227x227 pixel size)로 찌그려뜨린다(Warping).
3. 2000개의 Warped image를 각각 CNN 모델에 집어 넣는다.
4. 각각 Classification을 진행하여 결과를 도출한다.
몇 번 강조했듯이 R-CNN은 2-stage Detector로서
전체 Task를 두 가지 단계로 나누어 진행합니다.
첫 번째 단계는 Region Proposal (물체의 위치를 찾는 일)
두 번째 단계는 Region Classification (물체를 분류하는 일)
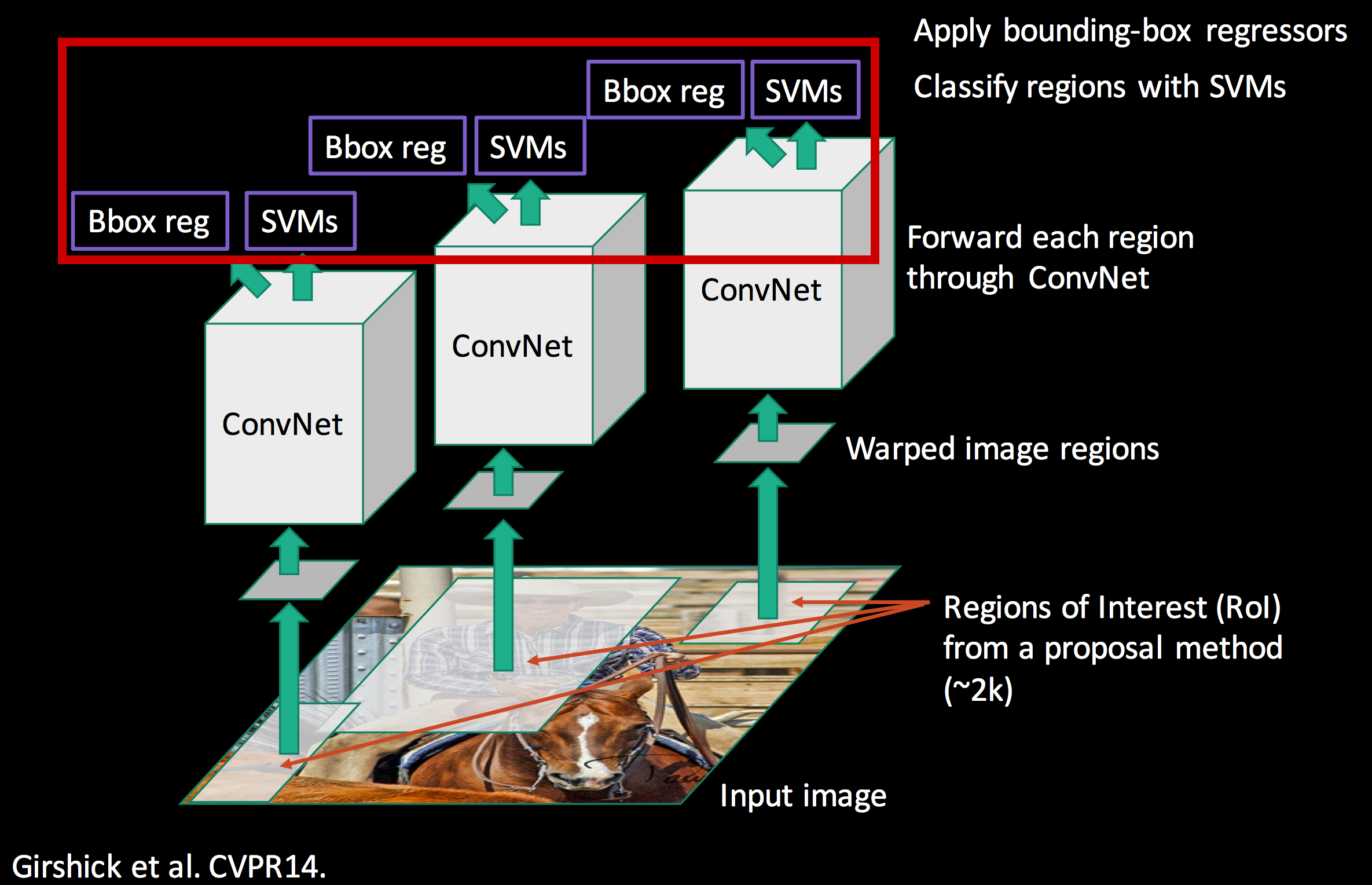
이 논문에서는 위 두 Task들을 행하기 위해 구조를 총 세 가지 모듈로 나누어 놓았습니다.
1. Region Proposal - 카테고리와 무관하게 물체의 영역을 찾는 모듈
2. CNN - 각각의 영역으로부터 고정된 크기의 Feature Vector를 뽑아내는 Large Convolutional Neural Network
3. SVM - Classification 을 위한 선형 지도학습 모델 Support Vector Machine(SVM)
위 세 가지 구조를 토대로 R-CNN의 흐름을 파악해보도록 하겠습니다.
1. Region Proposal (영역 찾기)

R-CNN의 구조를 조금 더 자세히 살펴보면 다음과 같습니다.
R-CNN은 Region Proposal 단계에서 Selective Search라는 알고리즘을 이용하였습니다.

Selective Search알고리즘은 Segmentation 분야에 많이 쓰이는 알고리즘이며,
객체와 주변간의 색감(Color), 질감(Texture) 차이, 다른 물체에 애워쌓여있는지(Enclosed) 여부 등을 파악해서
다양한 전략으로 물체의 위치를 파악할 수 있도록 하는 알고리즘입니다.
그림7과 같이 Bounding box들을 Random 하게 많이 생성을하고
이들을 조금씩 Merge 해나가면서 물체를 인식해나가는 방식으로 되어있습니다.
이 알고리즘에 대해서는 자세히는 다루지 않고,
"물체의 위치를 파악하기 위한 알고리즘이구나" 정도로 생각하고 넘어가겠습니다.
원리가 궁금하신 분들은 아래 논문 링크를 통해 확인하시면 되겠습니다.
(TMI: Selective Search와 비교되어 많이 설명되는 방법애는 Sliding Window 방법이 있습니다.)
Selective Search 논문 : http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
R-CNN에서는 Selective Search 알고리즘을 통해 한 이미지에서 2000개의 Region을 뽑아내고,
이들을 모두 CNN에 넣기 위해 같은 사이즈(224x224)로 찌그러뜨려(?) 통일시키는 작업(Warping)을 거칩니다.
2. CNN (Convolutional Neural Network)

앞선 Selective Search를 통해 생성된 2000개의
224x224 Pixel Size로 Warping된 이미지를 각각 CNN에 넣어 줍니다.

여기서 CNN은 AlexNet의 구조를 거의 그대로 가져다 썼으며,
Object Detetion 용으로 마지막 부분만 조금 수정하였습니다.
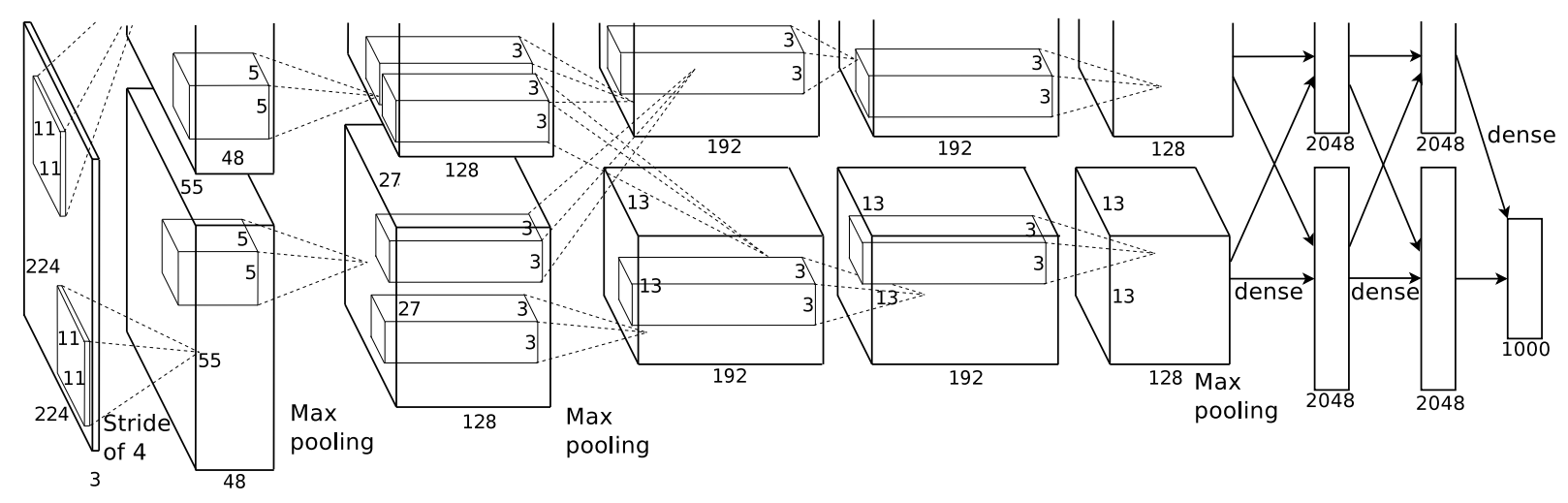
AlexNet Network 마지막 부분을 Detection을 위한 Class 수 만큼 바꾸고
(1000 -> PASCAL VOC 기준 20) (1000-> ILSVRC2013 기준 200)
Object Detection용 Dataset을 집어 넣어 Fine-Tuning을 진행하였습니다.
각각의 region proposal로부터 4096-dimentional feature vector를 뽑아내고,
이는 Fixed-length Feature Vector를 만들어냅니다.
3. SVM (Support Vector Machine)
CNN 모델로부터 Feature가 추출이 되고 Training Label이 적용되고 나면,
Linear SVM을 이용하여 classification을 진행합니다. (Category-Specific Linear SVMs)
여기서 의문점이 드는 분도 있을 수 있습니다.
" R-CNN은 왜 Classifier로 Softmax를 쓰지 않고 SVM을 사용하였을까? "
R-CNN 논문에서도 이를 Appendix B 부분에 기재해 두었는데요.
VOC2007 데이터셋 기준으로 Softmax를 사용하였을 때 mAP값이 54.2%에서 50.9%로 떨어졌다고 합니다.
이 논문에서는 CNN을 fine-tuning 할 때 이미지의 positive/negative examples와
SVM을 학습할 때 이미지의 positive/negative examples를 따로 정의했습니다.
CNN fine-tuning에서는 IoU가 0.5가 넘으면 positive이라고 두었고, 이 외에는 "background"라고 labeled 해두었습니다.
반면 SVM을 학습할 때는 ground-truth boxes만 positive example로 두었고
IoU가 0.3미만인 영역은 모두 negative로 두었으며, 나머지는 전부 무시했습니다.
SVM을 CNN fine-tuning과 같은 값을 두고 학습을 했을 때 훨신 성능이 안 좋게 나왔다고 하네요.
(IoU가 0.5에서 1 사이인 영역들(fine-tuning에서 positive으로 정의했던)을 "jittered examples"라고 정의하였습니다.)
Network의 Overfitting을 피하기 위해선 "jittered examples" 들이 분명 필요하지만,
시기상으로 fine-tuning 학습 데이터가 많지 않았기 때문에, 이러한 "jittered examples" 들이 다소 정확하지 않았고,
때문에 바로 Softmax Classifier를 적용시켰을 때 성능이 좋지 않아서
위와 같이 SVM을 학습하는 과정이 필요했던 것으로 보여집니다.
어찌됐든 SVM(Support Vector Machine)은
CNN으로부터 추출된 각각의 Feature Vector들의 점수를 Class별로 매기고,
객체인지 아닌지, 객체라면 어떤 객체인지 등을 판별하는 역할을 하는 Classifier입니다.
3-1 Bounding Box Regression
논문에서 소개했던 전체적인 구조는 위 세 가지 이지만
그림11에서도 보시다시피 bBox reg라고 쓰여진 상자를 하나 따로 빼놓았습니다.
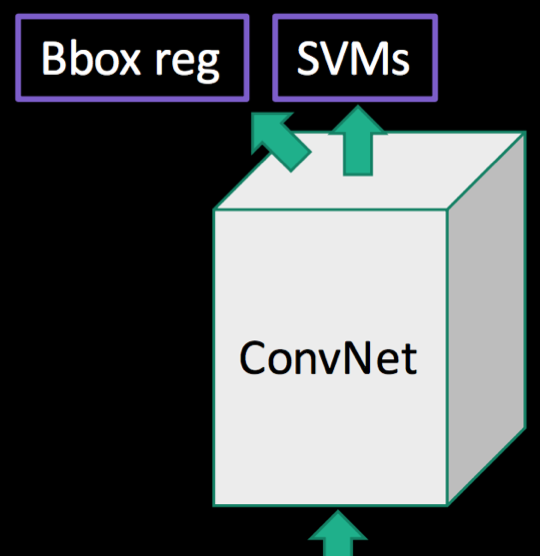
Selective Search로 만들어낸 Bounding Box는 아무래도 완전히 정확하지는 않기 때문에
물체를 정확히 감싸도록 조정해주는 선형회귀 모델(Bounding Box Regression)을 넣었습니다.
논문에서는 Appendix C 부분에 자세하게 잘 설명을 해 두었으니 이해가 안되시면 참고하시면 되겠습니다.

bBox의 input값은 N개의 Training Pairs로 이루어져 있습니다.
x, y, w, h는 각각 Bounding Box의 x, y 좌표 (위치), width(너비), height(높이)를 뜻합니다.
P는 선택된 Bounding Box이고 G는 Ground Truth(실제 값) Bounding Box입니다.
선택된 P를 G에 맞추도록 transform 하는 것을 학습하는 것이 Bounding Box Regression의 목표입니다.
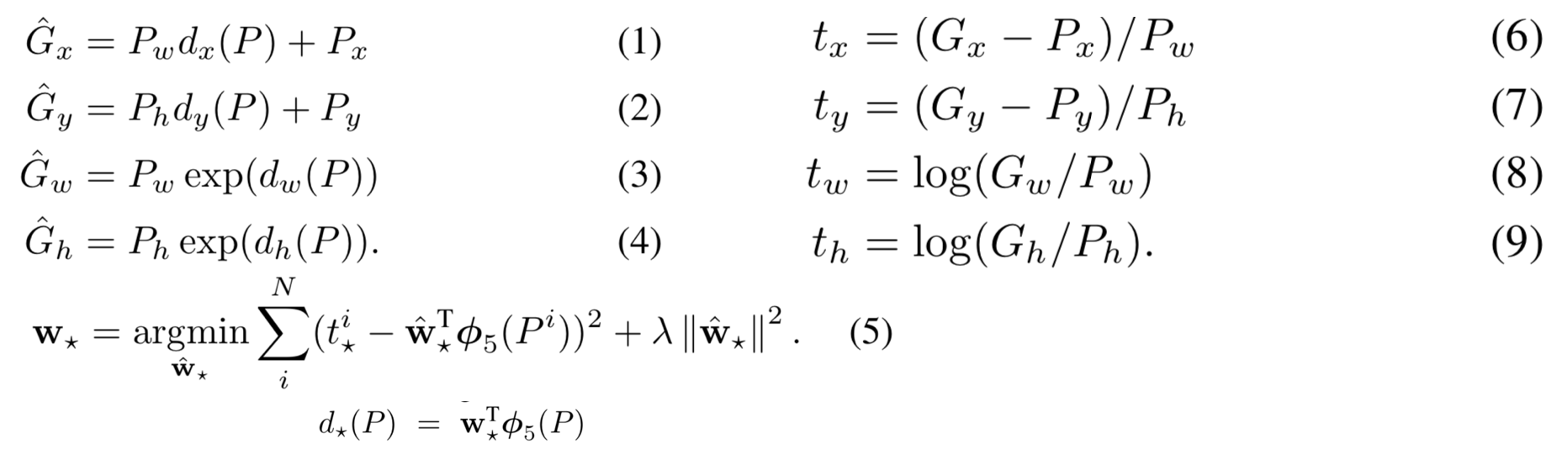
Bounding Box Regression의 수식은 그렇게 어렵진 않고,
앞으로 다루게 될 R-CNN계열의 방법의 Bounding Box Regression에서 모두 이 공식을 사용하게 됩니다.
(1), (2), (3), (4) 식에서 G hat들은 G(Ground Truth)와 최대한 가까워질 변수,
(1), (2), (3), (4) 식에서 G hat을 G(Ground Truth)로 바꾸고 d를 t로 치환하여 t에 대해 나타낸 것이 (6), (7), (8), (9) 식입니다.
(6), (7), (8), (9) 는 실제 값이 되겠죠?
(5)식에서 시그마(Sigma) 안에있는 식이 Loss Function입니다.
t와 d의 차이인 Loss를 줄여나가는 방향으로 학습 하는 것이
Bounding Box Regression 수식의 목표입니다.
뒤에 더해지는 람다 어쩌구 식은 Regularization 이고, 논문에서는 이 값이 중요하다고 기재되어 있습니다.
그리고 논문에서는 validation set을 기반으로 람다값을 1000으로 두었습니다.

위 그림에서 R-CNN BB라고 기재되어있는 맨 아래 행은 Bounding Box Regression을 적용한 경우 입니다.
Bounding Box Regression을 적용시켰을 때 성능이 더 향상 되는 것을 확인할 수 있습니다.
또 VOC 2010 데이터셋 기준으로 이전 방법들 보다 뛰어난 성능을 보입니다.
⊙ R-CNN의 단점 및 결론
R-CNN은 이전 Object Detection 방법들에 비해 굉장히 뛰어난 성능을 보였다는 것은 분명하지만
명확한 몇몇 단점들을 가지고 있습니다.
1. 오래걸린다
앞서 설명드렸듯이 R-CNN은
Selective Search에서 뽑아낸 2000개의 영역 이미지들에 대해서 모두 CNN모델에 때려 박습니다.
당연히 오래걸릴 수 밖에 없는 구조가 되겠죠?
그리고 Region Proposal에 사용되는 Selective Search가 CPU를 사용하는 알고리즘인 이유도
오래걸리는 이유 중에 하나입니다.
R-CNN의 수행시간은 아래와 같습니다.
Training Time: 무려 84시간
Testing Time은 GPU K40 사용 기준으로 frame당 13초
CPU를 사용하였을 때 frame당 53초가 걸립니다.
최근에 나온 논문들에 비하면 말도 안될만큼 오래 걸리는 것을 확인할 수 있습니다.
2. 복잡하다
위에서도 설명했다시피
R-CNN은 Multi-Stage Training을 수행하며,
CNN, SVM, 그리고 Bounding Box Regression까지 총 세 가지의 모델을 필요로 하는 복잡한 구조입니다.
3. Back Propagation이 안된다.
R-CNN은 Multi-Stage Training을 수행,
SVM, Bounding Box Regression에서 학습한 결과가 CNN을 업데이트 시키지 못합니다.
이러한 단점들이 존재하지만
R-CNN은 최초로 Object Detection에 Deep Learning 방법인 CNN을 적용시켰다는 점과
이후 2-stage detector들의 구조에 막대한 영향을 미쳤다는 점에서 의미가 큰 논문입니다.
다음 포스팅에서는 위 R-CNN의 문제점을 해결하고, 성능을 더 발전시켰던
R-CNN 계보의 뒷 논문들(Fast-RCNN, Faster R-CNN)을 소개해드리도록 하겠습니다 :)
https://nuggy875.tistory.com/33?category=860935
[Object Detection] 3. Fast R-CNN & Faster R-CNN 논문 리뷰
저번 포스팅에서는 CNN을 이용한 첫 Object Detection인 R-CNN을 알아봤습니다. https://nuggy875.tistory.com/21?category=860935 [Object Detection] 2. R-CNN : 딥러닝을 이용한 첫 2-stage Detector 저번 포스..
nuggy875.tistory.com
출처 : https://arxiv.org/abs/1311.2524 (R-CNN 논문)
https://www.saagie.com/blog/object-detection-part1/ (Object Detection 설명)
https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4 (RCNN계열 설명)
http://www.huppelen.nl/publications/selectiveSearchDraft.pdf (Selective Search)
https://arxiv.org/pdf/1312.6229.pdf (OverFeat)