
티스토리 뷰
[Object Detection] CenterNet (Objects as Points) 논문 리뷰
제이스핀 2019. 8. 17. 16:27지금까지 Real-Time Task를 요구하는 Object Detection 문제를 요구하는 프로젝트를 진행할 때는
주로 YOLO(You Look Only Once)를 사용하였습니다.
최근 빠른 성능(FPS)을 가지는 Detector를 요구하는 프로젝트를 진행하게 되어
YOLO말고 더 좋은 Real-time Detector는 없을까... 찾아보다가
꽤나 흥미로운 논문을 발견하게 되어 논문 리뷰를 진행하고자 합니다!

↓↓↓ CenterNet (Objects as Points) 논문 링크 ↓↓↓
https://arxiv.org/pdf/1904.07850v2.pdf
↓↓↓ CenterNet (Objects as Points) 코드 링크 ↓↓↓
https://github.com/xingyizhou/CenterNet
TMI : CenterNet은 두 개의 논문이 있습니다.
둘 다 성능이 다른 의미로 좋아서 헷갈려하시는 분들이 많더라구요...
1. Objects as Points (Xingyi Zhou et al.)
2. CenterNet: Keypoint Triplets for Object Detection (Kaiwen Duan et al.)
제가 리뷰하는 논문은 1. Objects as Points 입니다.
⊙ CenterNet은 One-stage Detector입니다.

CenterNet은 Anchor box를 사용하는
기존의 One-Stage Detector(RetinaNet, SSD, YOLO) 들과 비슷한 접근방식을 보입니다...만
극명한 차이점이 있습니다.
차이점1. CenterNet은 box overlap이 아닌 오직 위치만 가지고 "Anchor"를 할당합니다.
차이점2. CenterNet은 오직 하나의 "Anchor"만을 사용합니다.
차이점3. CenterNet은 더 큰 output resolution (output stride of 4) 을 가집니다.
이전의 One-Stage Detector들은 대부분 많은 수의 Anchor box들을 사용하여
최종 Bounding box들을 유추해 내었습니다.

DSSD (Fu et al., 2017) 의 경우에는 40k개가 넘는,
RetinaNet (Lin et al., 2017) 의 경우에는 100k개가 넘는 Anchor box들을 사용하였고,
이는 할당된 Anchor box가 실제값인 ground truth box와
충분히 overlap 될 수 있도록 하기 위함이었습니다 (box overlap).

하지만 이렇게 많은 Anchor box를 사용하게 되면, 정확도는 물론 높아지겠지만
Positive Anchor Box와 Negative Anchor box 사이의 불균형을 만들게 되고,
이는 당연히 training 속도를 늦추게 됩니다...
또한 많은 수의 Anchor box는 어떤 사이즈로 할지, 어떤 비율로 할지, 등
많은 수의 hyperparameter와 많은 수의 선택지들을 만들어 냅니다.
CornerNet (ECCV 2018) 은 Anchor box를 사용하는 것에 대한 약점을 위와 같이 열거 하였고,
Key point Estimation을 사용하여 고정적이지 않은 단 하나의 Anchor를 사용하는 방법을 소개한 바 있습니다.
CenterNet은 이 Key point Estimation을 사용하여 Detection을 진행합니다.
TMI : 어떤 논문에서는 Key Point Estimation 에서 Anchor를 사용하지 않는다고 하고,
어떤 논문에서는 고정적이지 않은 하나의 Anchor만을 사용한다고 표현합니다.
Anchor box는 보통 bounding box의 후보로서 많은 box들을 일컬으므로
둘 다 맞는 말이라고 볼 수도 있겠습니다.
저는 CenterNet 저자가 기술했듯이 하나의 Anchor를 사용한다고 기술하겠습니다.
⊙ Keypoint Estimation for Object Detection
CenterNet은 단 하나의 Anchor를 Keypoint Estimation을 통해서 얻어낼 수 있고,
이러한 방법은 CornerNet에서 처음으로 소개된 바 있습니다.
CornerNet
(ECCV 2018)
https://arxiv.org/pdf/1808.01244.pdf
Keypoints로 왼쪽 위, 오른쪽 아래, 두 개의 모서리를 Detect 하여 Bounding box를 얻어냅니다.

ExtremeNet
(CVPR 2019) (동일 저자)
https://arxiv.org/pdf/1901.08043.pdf
Keypoints로 top-most, left-most, bottom-most, right-most, center 점들을 Detect하여 Bounding box를 얻어냅니다.

CornerNet, ExtremeNet 둘 다 CenterNet 과 같은 robust한 keypoint estimation network에서 build 됩니다.
단, keypoint들에 대한 grouping 과정이 필요하여, 이는 알고리즘의 속도를 늦춥니다.
CenterNet은
물체마다 단 하나의 Keypoint인
중심점(Center Point)을 Estimate 합니다.
이로써 각 물체들은 모두 하나의 점(Key point)으로 표현이 됩니다.
따라서, grouping 과정이나 post-processing 과정(ex. NMS)들이 필요 없게 되고,
단 하나의 Anchor를 가지게 됩니다.
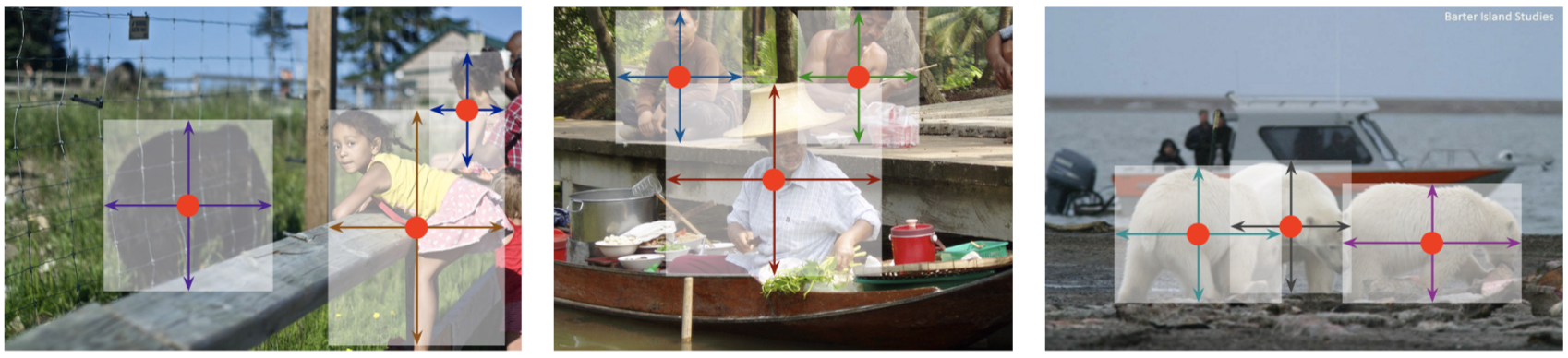
또한 흥미로운 점은
예측된 중심점으로 부터 CenterNet은
Object size, Dimension, 3D extent, Orientation, Pose 등 다양한 정보를 regress 하여
Object Detection 분야 뿐 아니라
3D Object Detection과 Multi-person Human Pose Estimation으로
쉽게 확장할 수 있습니다.
Github 데모 코드를 보면 세 종류의 Task를 수행하는 것을 확인할 수 있습니다.
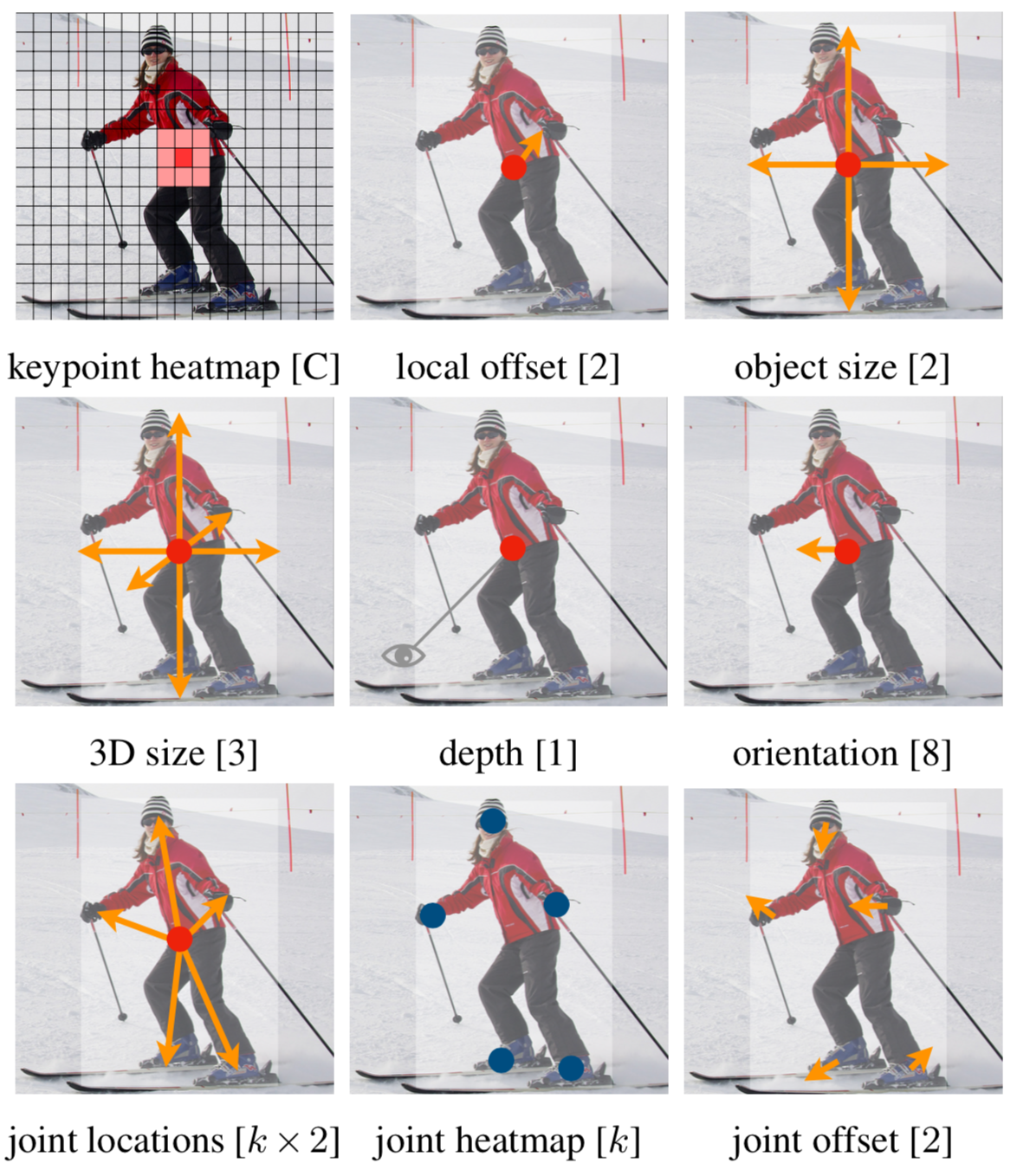
(1행) Object Detection을 위한 정보. (2행) 3D Object Detection을 위한 정보. (3행) Pose Estimation을 위한 정보
그렇다면 이 중심점을 어떻게 찾아낼까요??
⊙ Keypoint Estimation이란?
Key Estimation은 사실 Pose Estimation 분야에서 주로 많이 쓰이는 방법입니다.
Pose Estimation은 아래 영상을 보시면 바로 이해하실 수 있습니다.
https://www.youtube.com/watch?v=pW6nZXeWlGM&t=15s
Pose Estimation에서의 Keypoints들은
머리, 목, 어깨, 팔꿈치, 손목, 무릎, 등이 있습니다.
Pose Estimation에서 이러한 Keypoints들을 예측하는 데에 자주 쓰이는 알고리즘이
Keypoint Estimation 입니다.
CenterNet의 keypoint는 Object의 중심점이고,
CenterNet의 우선적인 목적은 network를 통해 keypoint heatmap을 얻어내는 데에 있습니다.

CenterNet은
4개의 architecture(Fully-Convolutional Encoder-Decoder Network)에서 학습을 진행하여
위 그림의 왼쪽 사진과 같은 Heatmap을 예측합니다
ResNet-18 , ResNet-101 , DLA-34 , Hourglass-104
(ResNet) Deep residual learning for image recognition. In CVPR, 2016.
(DLA) Deep layer aggregation. In CVPR, 2018.
(HourGlass) Stacked hourglass networks for human pose estimation. In ECCV, 2016
⊙ CenterNet의 구조
그리고 CenterNet은 CornerNet과 동일한 네트워크를 사용하여 Keypoint Prediction을 진행합니다.
CenterNet 논문에는 전체적인 구조에 대한 그림이 없어 CornerNet으로 부터 가져와봤습니다.

CenterNet은 위 CornerNet 구조를 거의 비슷하게 따라합니다.

위 CenterNet 그림은 제가 그린 것으로 정확하지 않을 수 있음을 알려드립니다...

CenterNet은 keypoints, offset, object size를 predict 하기 위해서 하나의 네트워크를 사용합니다.
1. keypoints
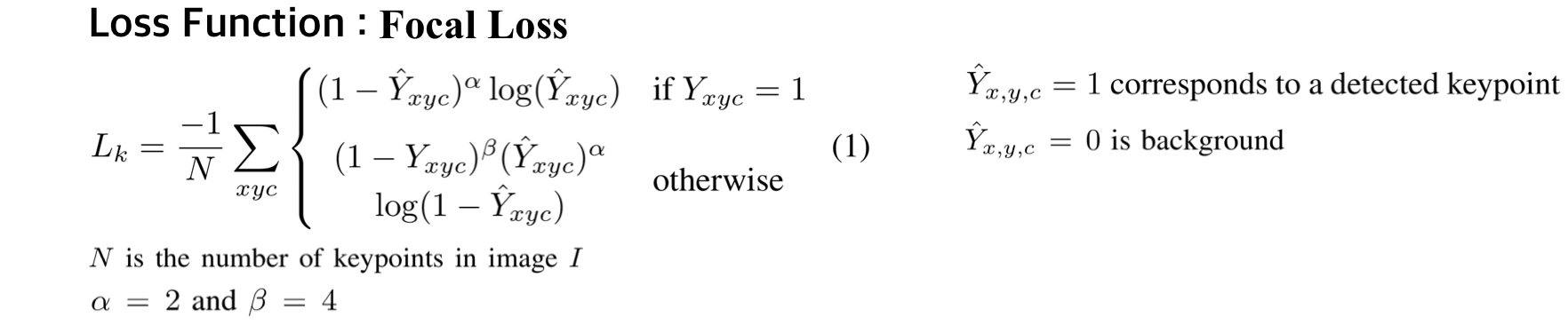
Keypoint 학습에는
Hard Positives (keypoint) << Easy Negatives (background)에 적합한
RetinaNet의 Focal Loss를 사용하였습니다.
2. Offsets
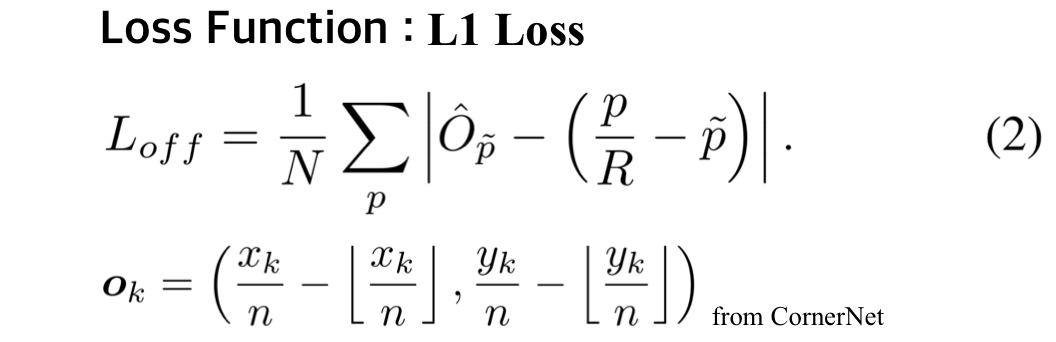
이미지가 Network를 통과하게 되면 output의 사이즈는 보통 이미지보다 줄어듭니다.
예측된 heatmap에서 keypoint들의 위치를 다시 input image로 remapping 할 때,
정확성이 떨어질 가능성이 있습니다.
이를 조정해주는 변수가 Offset입니다. (CornerNet에서 적용한 방법)
Offset 학습의 loss function에는 L1 Loss를 사용하였습니다.
3. Object Sizes

CenterNet은 측정한 keypoint로부터 추가적으로 object size를 regress합니다.
Object size 학습에는 L1 Loss를 사용하였습니다.
4. Overall Training Objective

CenterNet은 Keypoints, Offset, Size를 predict 하기 위해 Single Network를 사용합니다.
All outputs share a common fully-convolutional backbone Network!
⊙ From points to Bounding Boxes
이제 Object Detection을 진행하기 위해
keypoint로부터 Bounding box를 얻어낼 차례입니다.
CenterNet은 우선 heatmap으로부터 각 Category마다 peaks들을 뽑아 냅니다.

heatmap 에서 주변 8개 pixel보다 값이 크거나 같은 중간값들을 모두 저장하고,
값이 큰 100개의 peak들을 남겨놓습니다.

뽑아낸 peaks (keypoints) 의 위치는 정수 형태인 (x, y)로 나타내어지고,
이를 통해 bounding box의 좌표를 아래와 같이 나타낼 수 있습니다.
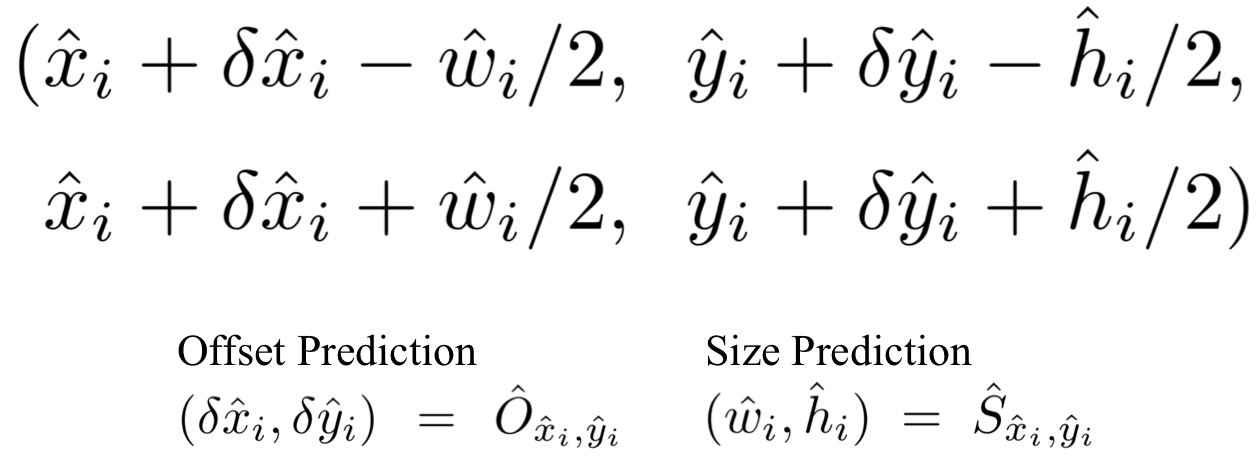
CenterNet이 강조하는 점은 이러한 모든 Ouput 들은
Single Keypoint Estimation으로 부터 나왔다는 것입니다.
⊙ CenterNet의 성능
CenterNet은 말씀드렸다시피
4개의 네트워크 모델을 사용하여 training을 진행하였습니다.

위 성능은 COCO 데이터셋 기준입니다.
개인적으로 놀라웠던건 ResNet-18을 사용하였을 때 FPS가 142까지 나왔다는 점과,
간단한 구조임에도 Hourglass-104를 Multi-scale로 돌렸을때
mAP가 45.1가 나왔다는 점입니다.

다른 SOTA 논문들과 비교해봤을때도 성능면에서 크게 차이가 나진 않습니다.
하지만 이 논문은 reject되었다고 들었는데요...
(어떤 학회인지는 잘 모르겠습니다)
제 주관적인 의견으로는
새로운 구조를 보인 것이 아니므로 성능으로 승부를 본 것인데
HG를 사용했을 때는 성능이 뛰어나지만 SOTA까지의 성능은 아니고,
DLA를 사용하였을 때는 성능 속도 둘다 뛰어나지만 현존하는 논문들과 비교하면 뭔가 애매... 합니다.
ResNet-18을 사용했을 때는 속도는 빠르지만 다른 논문들과 비교했을 때 성능이 뛰어나지는 않습니다.
Contribution 측면으로 봤을 때 부족한 점이 없지 않아 있어서 reject이 된 것이 아닌가... 조심스래 예상해봅니다 ㅎㅎ
무엇보다 개인적으로 이 논문이 맘에 들었던건
github 코드구현이 깔끔하게 잘 되있어서
누구나 쉽게 데모 테스트를 해볼 수 있도록 해두었던 것이 좋았던 것 같습니다!
출처 : https://arxiv.org/pdf/1904.07850v2.pdf (CenterNet: Object as Points)
https://github.com/xingyizhou/CenterNet (CenterNet: Object as Points 코드)
https://arxiv.org/pdf/1904.07850v2.pdf (CenterNet: Keypoint Triplets for Object Detection)
https://arxiv.org/pdf/1512.02325.pdf (SSD)
https://arxiv.org/pdf/1701.06659.pdf (DSSD)
https://arxiv.org/pdf/1708.02002.pdf (RetinaNet)
https://arxiv.org/pdf/1808.01244.pdf (CornerNet)
https://arxiv.org/pdf/1901.08043.pdf (ExtremeNet)
'CV & ML > Object Detection' 카테고리의 다른 글
| Windows 에서 pycocotools 설치 (0) | 2022.02.23 |
|---|---|
| [3D Object Detection] 3D Object Detection 논문 흐름 및 리뷰 (1) | 2022.01.04 |
| [Object Detection] 3. Fast R-CNN & Faster R-CNN 논문 리뷰 (27) | 2019.08.17 |
| [Object Detection] 2. R-CNN : 딥러닝을 이용한 첫 2-stage Detector (18) | 2019.04.03 |
| [Object Detection] 1. Object Detection 논문 흐름 및 리뷰 (14) | 2019.03.28 |
- Total
- Today
- Yesterday
- CUDA
- Python
- git
- Macbook
- Anaconda
- GPU
- 우분투
- Object Detection
- Android
- java
- pytorch
- 2-stage Detector
- Deep Learning
- nvidia
- MySQL
- error
- ubuntu
- nerf
- Machine Learning
- Computer Vision
- vscode
- GaussianSplatting
- SSH
- Docker
- nginx
- Novel View Synthesis
- numpy
- 3Dvision
- Neural Radiance Field
- MacOS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |